
The best of GAN papers in the year 2018 (part 2)
As a follow-up to my previous post, where I discussed three major contributions to GANs (Generative Adversarial Networks) domain, I am happy to present another three interesting research papers from 2018. Once again, the order is purely random and the choice very subjective.
- Large Scale GAN Training for High Fidelity Natural Image Synthesis - DeepMind’s BigGAN uses the power of hundreds of cores of a Google TPU v3 Pod to create high-resolution images on a large scale.
- The relativistic discriminator: a key element missing from standard GAN - the author proposes to improve the fundamentals of GANs by introducing an improved discriminator.
- ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks - the Super-Resolution GAN (SRGAN) from 2017 was one the best networks which map low-resolution images to their high-resolution equivalents. This work improves SRGAN through several interesting tricks. Some may say that this is just incremental improvement, but the implemented ideas are really clever!
Large Scale GAN Training for High Fidelity Natural Image Synthesis
Details
The paper has been submitted on 28.09.2018. You can easily run BigGAN using Google Collab.
Main idea:

Even though the progress in the domain of GANs is impressive, image generation using Deep Neural Networks remains difficult. Despite the great interest in this field, I believe that there is a lot of untapped potential when it comes to generating images. One of the ways to track the progress of GANs and measure their quality is Inception Score (IS). This metric considers both quality of generated images as well as their diversity. Using the example of 128x128 images from ImageNet dataset as our baseline, the real images from the dataset achieve \(IS = 233\). While the state-of-the-art was estimated at \(IS = 52.5\), BigGAN has set the bar at \(IS = 166.3\)! How is this possible? The authors show how GANs can benefit from training at large scale. Leveraging the immense computational resources allows for dramatic boost of performance, while keeping the training process relatively stable. This allows for creation of high resolution images (512x512) of unparalleled quality. Among many clever solutions to instability problem, this paper also introduces the truncation trick, which I have already discussed in part 1 of my summary (A Style-Based Generator Architecture for Generative Adversarial Networks).
The method:
In contrast to other papers I evaluated, the significance of this research does not come from any significant modification to the GAN framework. Here, the major contribution comes from using massive amounts of computational power available (courtesy of Google) to make the training more powerful. This involves using larger models (4-fold increase of network parameters with respect to prior art) and larger batches (increase by almost an order of magnitude). This turns out to be very beneficial:
- Using large batch sizes (2048 images in one batch) allows every batch to cover more modes. This way the discriminator and generator benefit from better gradients.
- Doubling the width (number of channels) in every layer increases the capacity of the model and thus contributes to much better performance. Interestingly, increasing the depth has negative influence on the performance.
- Additional use of class embeddings accelerates the training procedure. Using class embeddings means conditioning the output of the generator on dataset’s class labels.
- Finally, the method also benefits from hierarchical latent spaces - injecting the noise vector \(\textbf{z}\) into multiple layers rather then solely at the initial layer. This not only improves performance of the network, but also accelerates the training process.
Results:
Large scale training allows for superior quality of generated images. However, it comes with its own challenges, such as instability. The authors show, that even though the stability can be enforced through regularization methods (especially on the discriminator), the quality of the network is bound to suffer. The clever workaround is to relax the constraints on the weights and allow for training to collapse at the later stages. Then, we may apply the early stopping technique to pick the set of weights just before the collapse. Those weights are usually sufficiently good to achieve impressive results.


The relativistic discriminator: a key element missing from standard GAN
Details
The paper has been submitted on 02.06.2018. One of the reasons why this research is impressive is the fact, that it seems that the whole job was done by one person. The author thought about everything - writing a short blog post about her invention, publishing well documented source code and starting an interesting discussion on reddit.
Main idea:
In standard generative adversarial networks, the discriminator \(D\) estimates the probability of the input data being real or not. The generator \(G\) tries to increase the probability that generated data is real. During training, in every iteration, we input two equal-sized batches of data into the discriminator: one batch comes from a real distribution \(\mathbb{P}\), the other from fake distribution \(\mathbb{Q}\). This valuable piece of information, that half of the examined data comes from fake distribution is usually not conveyed in the algorithm. Additionally, in standard GAN framework, the generator attempts to make fake images look more real, but there is no notion that the generated images can be actually “more real” then real images. The author claims that those are the missing pieces, which should have been incorporated into standard GAN framework in the first place. Due to those limitations, it is suggested that training the generator should not only increase the probability that fake data is real but also decrease the probability that real data is real. This observation is also motivated by the IPM-based GANs, which actually benefit from the presence of relativistic discriminator.
The method:
In order to shift from standard GAN into “relativistic” GAN, we need to modify the discriminator. A very simple example of a Relativistic GAN (RGAN) can be conceptualized in a following way:
In standard formulation, the discriminator may be a function
\[D(x) = \sigma(C(x))\]\(x\) is an image (real or fake), \(C(x)\) is a function which assigns a score to the input image (evaluates how realistic \(x\) is) and \(\sigma\) translates the score into a probability between zero to one. If discriminator receives an image which looks fake, it would assign a very low score and thus low probability, for example: \(D(x) = \sigma(-10)=0\) On the contrary, real-looking input gives us high score and high probability, for example: \(D(x) = \sigma(5)=1\)
Now, in relativistic GAN, the discriminator estimates the probability that the real data \(x_r\) is more realistic then a randomly sampled fake data \(x_f\):
\[D(\widetilde{x}) = \sigma(C(x_r)-C(x_f))\]Where \(\widetilde{x} = (x_r,x_f)\). To make the relativistic discriminator act more globally and avoid randomness when sampling pairs, the author builds up on this concept to create a Relativistic average Discriminator (RaD).
\[\bar{D}(x)=\begin{cases} sigma(C(x)-\mathop{\mathbb{E}}_{x_{f}\sim\mathbb{Q}}C(x_{f})), & \text{if $x$ is real}\\ sigma(C(x)-\mathop{\mathbb{E}}_{x_{r}\sim\mathbb{P}}C(x_{r})), & \text{if $x$ is fake}. \end{cases}\]This means that whenever the discriminator \(\bar{D}(x)\) receives a real image, it evaluates how is this image more realistic that the average fake image from the batch in this iteration. Analogously, \(\bar{D}(x)\) receives a fake image, it is being compared to an average of all real images in a batch. This formulation of relativistic discriminator allows us to indirectly compare all possible combinations of real and fake data in the minibatch, without enforcing quadratic time complexity on the algorithm.
Results:
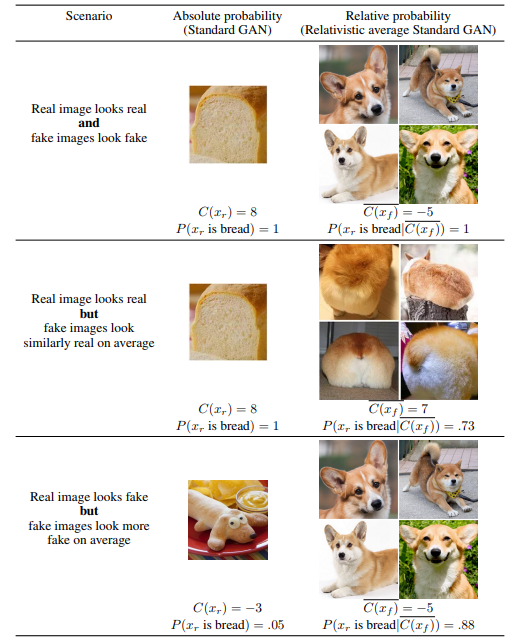
The diagram shows an example of the discriminator’s output in standard GAN:
\[P(x_r~ \text{is real}) = \sigma(C(x_r)))\]and RaD:
\[P(x_r~ \text{is real}|C(x_f)) = \sigma(C(x_r) − C(x_f)))\]\(x_f\) are dogs images while \(x_r\) are pictures of bread. I think that this example gives a very good intuitive understanding of the relativistic discriminator.

I have the impression that this paper may start a new trend - using relativistic discriminator in different GAN problems. The experiments indicate, that the approach may help with many problems such as stability or inferior image quality. It may also accelerate the networks’ training speed. I really love the fact, that the author has questioned a very fundamental element of the GAN architecture. It is exciting to see that there are already state-of-the-art publications which take advantage of relativistic discriminators (even though this paper came out in June). An example of such an architecture is…
ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks
Details
The paper has been submitted on 17.09.2018. The code is available publicly on github. Fun fact: several people have used ESRGAN to improve textures in some old games e.g Morrowind, Doom 2 or Return to Castle Wolfenstein.
Main idea:

The SRGAN was 2017’s state of the art invention in the domain of super-resolution (SR) algorithms. It’s task was to take a low resolution (LR) image and output its high resolution (HR) representation. The first optimization target of the network was to minimize the mean squared error (MSE) between recovered HR image and the ground truth. This is equivalent to maximizing peak signal-to-noise ratio (PSNR), which is a common measure used to evaluate SR algorithms. However, this favours overly smooth textures. That is why the second goal of the network was to minimize perceptual loss. This helps in capturing texture details and high frequency content. As the result, the network has learned to find a sweet spot between those two contradictory goals. By forcing the GAN to keep track of goals, the network produces high quality HR representation of the LR input. One year later, the SRGAN method (created by the scientists from Twitter), has been improved by Chinese and Singaporean researchers. The new network can create even more realistic textures with reduced number of artifacts. This has been achieved through several clever tricks.

The method:
The ESRGAN takes SRGAN and employs several clever tricks to improve the quality of the generated images. Those four improvements are:
- Introducing changes to the generator’s architecture (switching from Residual Blocks to RRDB, removing batch normalization).
- Replacing an ordinary discriminator with the relativistic discriminator (as described in the previously discussed paper).
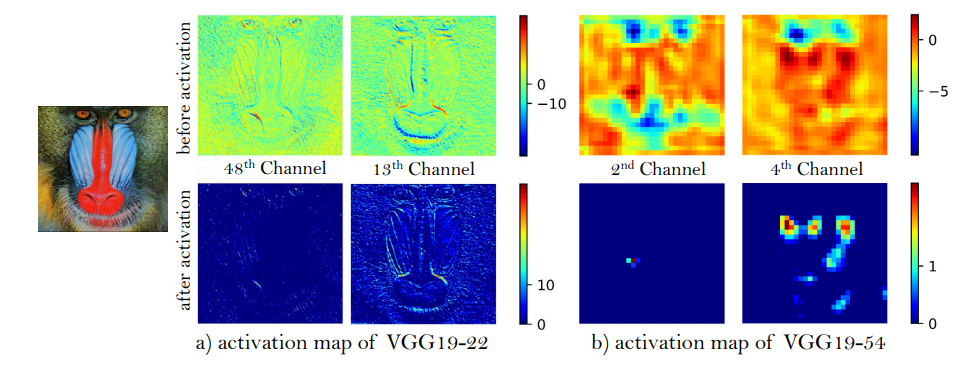
- Regarding perceptual loss, using feature maps before activation, rather then post-activation.
- Pre-training the network to first optimize for PSNR and then fine tune it with the GAN.
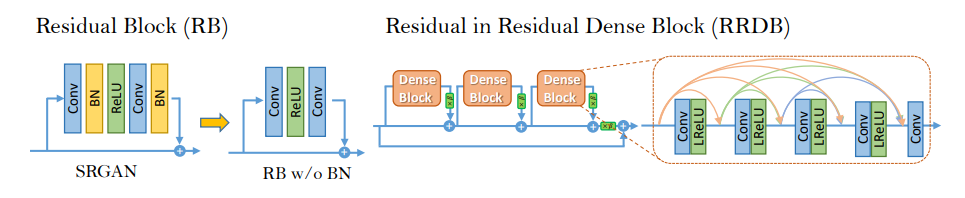
Introducing major changes to the network architecture - while the generator in the original SRGAN was using residual blocks, the ESRGAN additionally benefits from dense connections (as proposed by the authors of DenseNet). This not only allows for increased depth of the network, but also enforces more complex structure. This way the network can learn finer details. Additionally, ESRGAN does not use batch normalization. Learning how normalize the data distribution between layers is a general practice in many Deep Neural Networks. However, in case of SR algorithms (especially the ones which use GANs), it tends to introduce unpleasant artifacts and limits the generalization ability. Removing batch normalization improves the stability and reduces computational cost (less parameters to learn).
Replacing an ordinary discriminator with relativistic disciminator - it is really interesting that the idea of relativistic discriminator has been already employed by the community shortly after the paper has been published. Using the Relativistic average Discriminator allows the network not only to receive gradients from generated data, but also from the real data. This improves the quality of edges and textures.
Revisit perceptual loss - the perceptual loss attempts to compare perceptual similarity between the reconstructed image \(G(x_{LR})\) and the ground truth image \(x_{HR}\). By running both inputs through the pre-trained VGG network, we receive their representation in form of feature maps after j-th convolution and activation \(\phi(G(x_{LR}))\) and \(\phi(x_{HR})\). One of the tasks of the SRGAN was to minimize the difference between those representations. This is still the case in ESRGAN. However, we take the representation after j-th convolution but before activation.
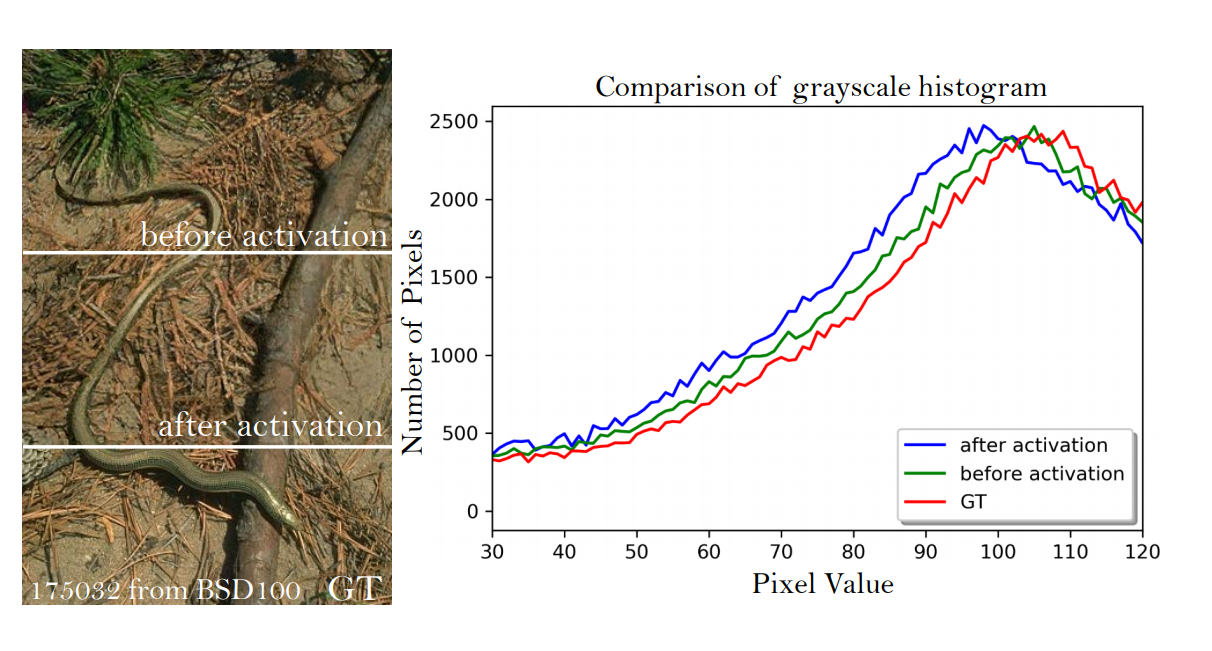
Network interpolation - as I have mentioned before, there are two goals which the algorithm tries to achieve. This is not only perceptual similarity between generated image and ground truth, but also lowest possible PSNR. This why initially the network is being trained to minimize PSNR (using L1 loss). Then, the pre-trained network is being used to initialize the generator. This not only allows to avoid undesired local minima for the generator, but also provides the discriminator with quite good super-resolved images from the start. The authors state that the best results can be obtained through interpolation between the weights of the initial network (after PSNR optimization) and final network (after GAN training). This allows to control the PSNR versus perceptual similarity trade-off.
Results:
The experiments are similar to the ones conducted on SRGAN. The goal is to scale the LR image by the factor of 4 and obtain a good quality SR image of size 128x128.
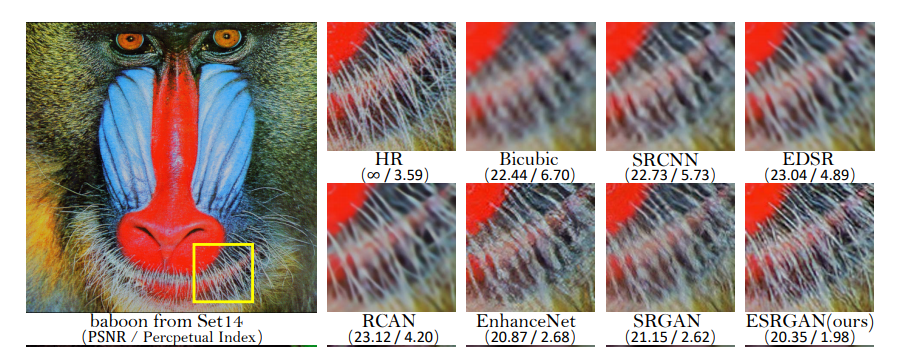

The authors have tested their network at the PIRM-SR challenge, where the ESRGAN has won the first place with the best perceptual index.
Those were my six favourite research papers, which have marry GANs and Computer Vision. If you would like to add or change something on this list, I would love to hear about your candidates! Have a great 2019 everybody!
All the figures are taken from the publications, which are being discussed in my blog post