
Project - Reinforcement Learning with Unity 3D: G.E.A.R
Over the course of the last several months I was working on a fantastic project organized by the Chair for Computer Aided Medical Procedures & Augmented Reality. As a result, together with a team of students, we have developed a prototype of an autonomous, intelligent agent for garbage collection. The idea has been born during a workshop organized by PhD students from the Technical University of Munich. This was start of a great journey, which required us to use our knowledge from the fields of Computer Vision, Deep Reinforcement Learning and Game Development to create a functional simulation of our robot, G.E.A.R - Garbage Evaporating Autonomous Robot. This blog post presents the details of the endeavour. Naturally, if you would like to tinker with the G.E.A.R or contribute further to our project, feel free to visit the repository: Reinforcement Learning With Unity-G.E.A.R.
Table of Contents
Project overview
Motivation:
No matter where you come from - the first things which comes to mind when you hear about Munich, the capital of Bavaria, is Oktoberfest. The famous beer festival is deeply rooted in the Bavarian culture. The scale of the event is impressive: the amount of people which visit Munich in autumn every year, the litres of beer drank by the visitors and the money which exchanges hands during the Oktoberfest - those numbers can be hardly compared to any other event in the world. Clearly, this means that one could find a financial incentive to be a part of this huge celebration. Additionally, as an engineer and researcher, my task is to solve (meaningful) problems. In this case, I could instantly spot one issue…
Oktoberfest is indeed exciting and fun for the participants. However, we tend to turn blind eye to things, which happen after the celebration is over. One of those things are the massive amounts of garbage generated each day of the Oktoberfest. At 10pm, when the visitors leave the Wiesn (the area where the Oktoberfest takes place), an army of sanitation workers rushes to clean up the garbage generated by a platoon of drunk guests. So far, this process is pretty much done by human workers. How about automating the task? Frankly speaking, this is not only a mundane and unfulfilling job. This is also a task which could be done much more efficient by robots. Especially by a hive of intelligent, autonomous robots, which can work 24/7. Such a collective of small robotic workers could accelerate the process of garbage collection by orders of magnitude, while simultaneously being very cost efficient.

Our first step is to simulate the robot using Unity 3D game engine. We additionally use the Unity Machine Learning Agents Toolkit (ML-Agents) plug-in that enables game scenes to serve as environments for training intelligent agents. This allows the user to train algorithms using reinforcement learning, imitation learning, neuroevolution, or other machine learning methods through a simple-to-use Python API.
Agent and Environment:

The setup for the agent is a Bavarian-themed room. The goal of a robot is to explore the environment and learn the proper reasoning (policy), which we indirectly enforce on G.E.A.R through a set of rewards and punishments.
The goal of the robot is:
- to approach and gather the collectibles (stale loaves of bread, red plastic cups and white sausages).
- not to collide with static objects (chairs and tables), slamming against the wall or collecting wooden trays (they belong to the owner of a Bavarian tent and should not be collected by the robot for future disposal).

The robot itself is modelled as a cube, which can roam around the room and collect relevant objects. It’s action vector contains three elements, which are responsible for:
- translational motion (move forward, backward, or remain stationary)
- heading angle (turn left, right or refuse to rotate)
- grabbing state (activate or not)
While the first two actions are pretty straightforward, one could ask what “grabbing state” is. Since the creation of an actual mechanism for garbage collection would be not only very time-consuming but also troublesome (Unity 3D is not as accurate as CAD software when it comes to modelling the physics of rigid bodies), we have decided to use a certain heuristic to simulate the collection of items. Every time the robot decides to collect an object, two requirements must be fulfilled:
- The object must be close to the front part of the robot (confined within the volume with green edges)
- The robot must decide to activate “a grabber”. When the grabbing state is activated, the colour of the robot changes from white to red.

This heuristic not only allows us to model the behaviour of an agent without an actual mechanical implementation of a grabber, but also allows to observe the reasoning of the agent and debug the behaviour of G.E.A.R.
Perception Cognition Action
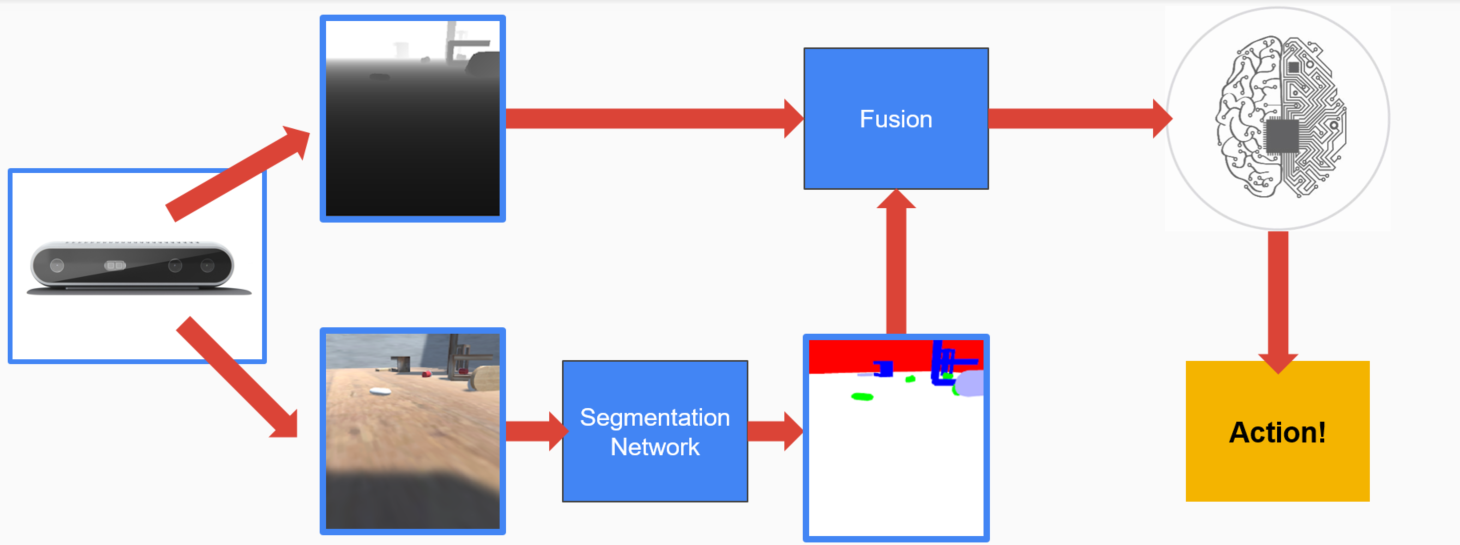
An intelligent system can be abstracted as an interplay between three systems: perception, cognition and action. In case of G.E.A.R, the perception is handled by an Intel RealSense camera. In every timestep, we simulate the input from the sensor by providing the robot with two pieces of information: an RGB frame as well as depth map. Now cognition comes into play. The RBG input is transformed into semantic segmentation maps which assign a class to every object in the image. This way the robot knows the class of each pixel in the RBG frame. Then the depth and semantic segmentation maps are fused together and analysed by the set of neural networks - the brain of the robot. Finally, the brain outputs a decision about robot’s action.
Punishments and Rewards
According to the reinforcement learning paradigm, the robot should be able to learn the proper policy through interaction with the environment and collection of feedback signals. For our agent, those signals are expressed as floats spanning from -1 to 0 (punishments) and from 0 to 1 (rewards).
The proper assignment of punishments and rewards and defining their values is challenging. During the project we have learned two important lessons. Those may not be applicable to all RL project, but should be kept in mind if you struggle with the similar tasks as ours:
First, try to get “good enough” policy quickly - we have noticed, that it is advisable to first present the agent with high rewards for the main goal, while giving only small (or no) feedback signals regarding secondary goals. This way we can quickly achieve a decent, general policy. This can be refined by fine-tuning the punishments and rewards later. This way we avoid being stuck in local minimum early on.
Curriculum learning is great when the problem is complex - it is shown by Bengio at al. 2009 that when want to learn a complex task, we should start with easier subtasks and gradually increase the difficulty of the assignments. This can be easily implemented in Unity ML-Agents and allows us to solve our learning task by breaking the project down into two subgoals: roaming the environment in search of garbage and deciding when to activate the grabbing state.
In the end, we have finished the training with the following set of rewards and punishments enforced on the agent (+++ is a very high reward equivalent to 1 while — is the biggest punishment of -1) :
| Action | Signal (Punishment or Reward) | Comment |
|---|---|---|
| Gathering the collectible | \(+++\) | The main goal is to collect the garbage. |
| Moving forward | \(+\) | Typically assigned in locomotion tasks. |
| Punishment per step | \(-\) | So that the agent has an incentive to finish the task quickly. |
| Activating the grabbing mechanism | \(-\) | In the real world, activating the grabber mechanism when unnecessary would be ridiculously energy inefficient. |
| Colliding with an obstacle | \(--\) | The initial punishment was low, so the robot learns not to strictly avoid the furniture but to manoeuvre between table legs etc. |
| Slamming against a wall | \(--\) | In rare cases robot can touch the wall, e.g. to pick an object positioned beside it. |
| Collecting a wooden tray | \(---\) | The robot needs to learn not to collect non-collectible items. |
The reddit user Flag_Red has pointed out the fact that the punishment per step is in fact redundant. The discount factor in the Bellman’s equation makes the agent prefer immidiate rewards to rewards which come in the future. This means that we do not need this particular signal. Thank you for the remark!
Additionally, there are many useful tips and tricks regarding the training procedure suggested by the authors of ML-Agents Toolkit.
Algorithms
Semantic Segmentation
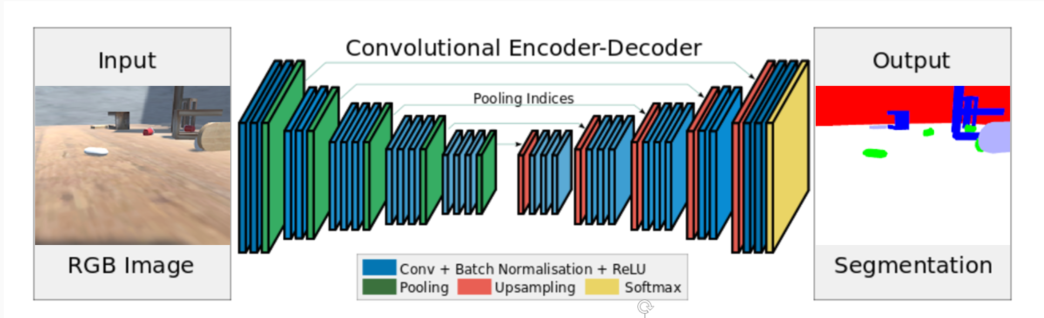
The robot itself does not know which object should be collected and which should be avoided. This information is obtained from a network, which maps the RBG image to a semantic segmentation maps. For the purpose of the project, we have created a dataset of 3007 pairs of images - RBG frames (input) and matching semantic segmentation maps (ground truth obtained from Unity 3D custom shader). We have used Semantic Segmentation Suite to quickly train the SegNet (Badrinarayan et al., 2015) model using our data. Even though SegNet is far from state of the art, given its simple structure (easy to debug and modify), relatively uncomplicated domain of the problem (artificial images, simple lightning conditions, repeatable environment) and additional requirements (as little project overhead as possible) it has turned out to be a good choice.



Brain of an Agent
The central part of robot’s cognition is the brain. This is the part responsible for the agent’s decision: given the current state of the world and my policy, which action should I take? To answer this questions, we have decided to employ several approaches:
Proximal Policy Optimization - PPO is current state-of-the-art family of policy gradient methods for reinforcement learning developed by OpenAI. It alternates between sampling data through interaction with the environment and optimizing a “surrogate” objective function using stochastic gradient ascent.
Behavioral Cloning from Observation - this approach frames our problem as supervised learning task. We “play the game” for half an hour in order for agent to clone our behaviour. Given this ground truth, the agent learns the rough desired policy.
Moreover, we have created our own Heuristic Approach, which will be explained in the next chapter.
Presentation of Solutions:
PPO
Our first approach involves training an agent using PPO algorithm. Here, the semantic segmentation information does not come from an external neural network. It is being generated using a shader in Unity, which segments the objects using tags. This means that the agent quickly receives reliable, noise-free information about objects’ classes during training. We additionally utilize two more modifications offered by Unity ML-Agents:
-
Memory-enhanced agents using Recurrent Neural Networks - this allows the agent not only to act on the current RGBD input, but also “to remember” the last \(n\) inputs and include this additional information into its reasoning while making decisions. We have observed that this has improved the ability of G.E.A.R to prioritize its actions e.g. the agent may sometimes ignore a single garbage item when it recognizes that there is an opportunity to collect two other items instead (higher reward), but eventually returns to collect the omitted garbage.
-
Using curiosity - when we face a problem, where the extrinsic signals are very sparse, the agent does not have enough information to figure out the correct policy. We may endow the agent with a sense of curiosity, which gives the robot an internal reward every time it discovers something surprising and unconventional with regard to its current knowledge. This encourages an agent to explore the world and be more “adventurous”. It is hard to say what was the influence of curiosity in our case, but we have noticed that there were several timepoints where the internal reward spiked during training and significantly improved the current policy of an agent.
It took us couple of days of curriculum training to train agent using PPO. We have observed that setting the punishments initially to high, encourages the agent to simply run in circles. This can be avoided by initially allowing the agent to figure out the main goal. Once the robot understands what it is being encouraged to do, we can impose further restraints in form of harsher punishments to fine tune the behaviour of G.E.A.R.
PPO with Segmentation Network
In real-life application, we could not use the custom shader in Unity 3D. That is why we should train our own model for semantic segmentation. When the model is ready, there are two possibilities to embed the SegNet into the Python API:
- Train the brain with SegNet in train time - this makes the training extremely time inefficient. Every input frame needs to be segmented by the SegNet which is too computationally expensive for our humble laptops. Additionally, the brain of the agent suffers from the SegNet’s imperfect output. On the other hand, this approach makes the implementation of SegNet in Python API quite straightforward.
- Train the brain using custom shader and plug in the SegNet during test time - this is more time-efficient solution, because SegNet is being used only at inference time. It also allows to train the brain of the agent using noise-free segmented images from the custom shader. Sadly, this requires much more work with Python API, to integrate SegNet post-factum.
Given our limited computational resources and desire to train the brain using perfect data, we have decided to choose the second option.
Behavioral Cloning
In this approach agent learns directly from human player. This has several implications: we can train a decent agent in half an hour or so, but it will never be better then a human. This approach may suffice to create an agent which is just good and not excellent in some task (e.g video game AI, where an agent should be weak enough so we can enjoy playing a game). Obviously, G.E.A.R trained using this method is not good enough for our purpose.
Heuristic
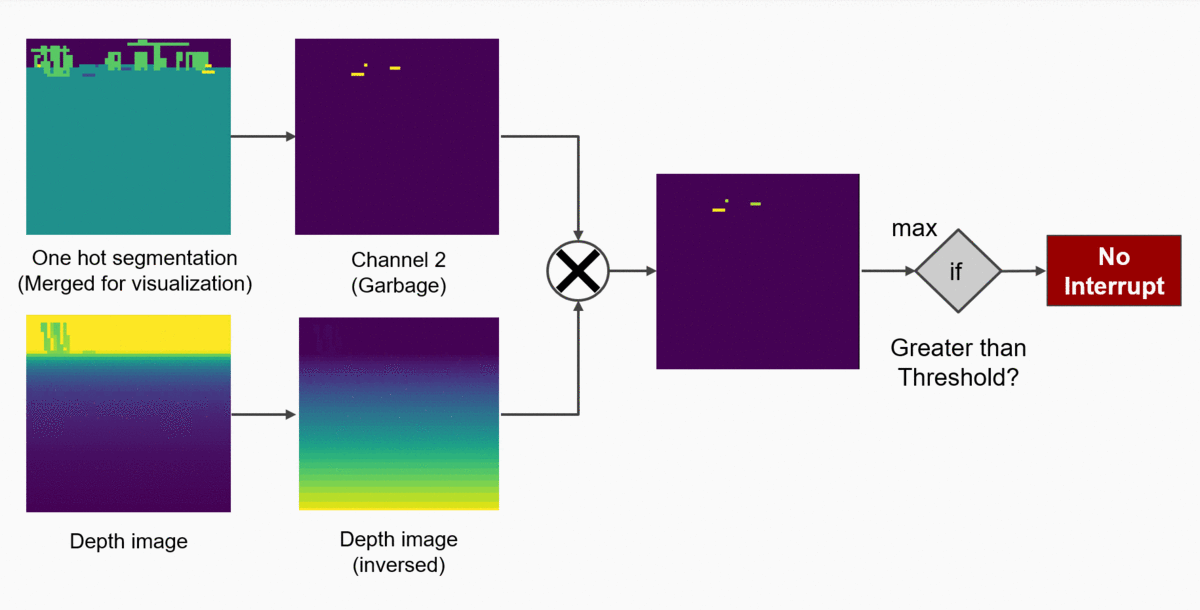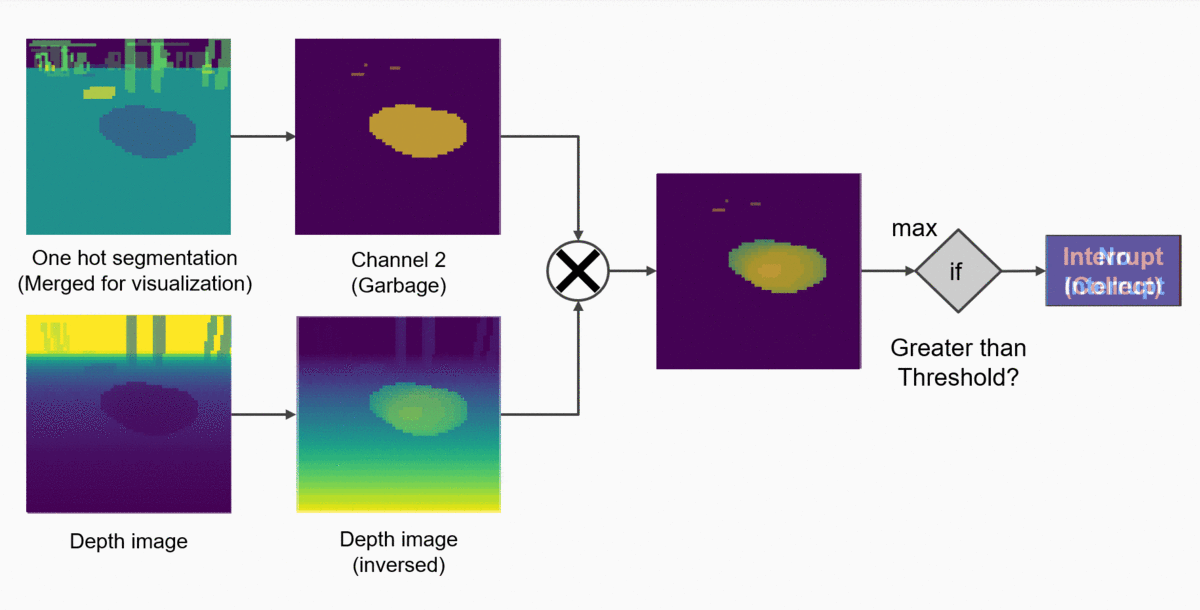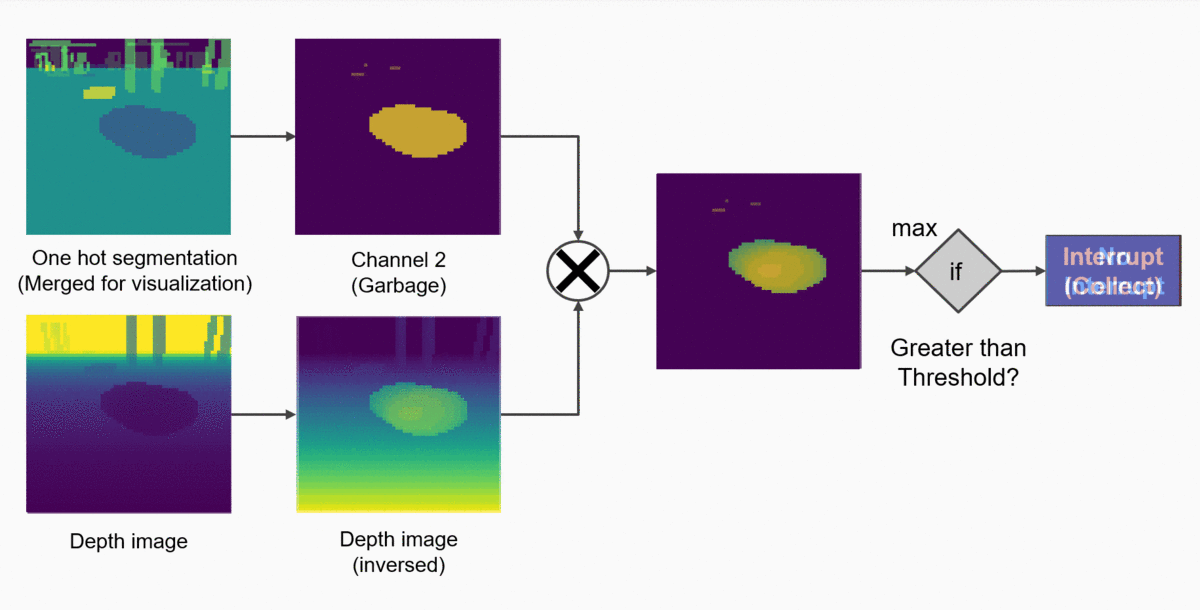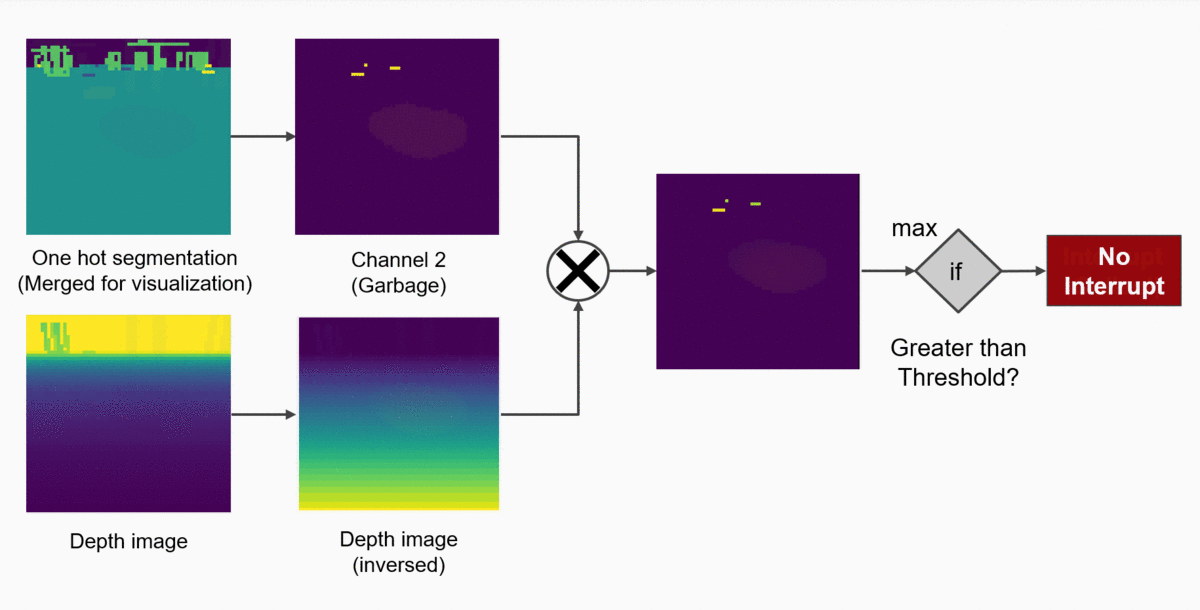
While planning the project, we have established that the robot’s behaviour consists in essence of two task: approaching the collectible objects and deciding if the garbage should be collected or not. So far, our agent has managed to figure out both assignments on its own. But just for fun (or maybe to accelerate the training process), we can “hard-code” the second objective - deciding if the garbage should be collected or not. The decision about activating the grabbing mechanism is just an output of a simple function, which takes into consideration two factors:
- The class of the object in front of us (defined by a semantic segmentation map)
- The distance of the object from our robot (provided by a depth map)
This function can be easily hard-coded in the following way:
- From the current depth map, filter out only those pixels which belong to the “collectible” class (overlaying a binary mask over the depth map).
- Check if the pixel with the highest value is greater than some set threshold.
- If yes: the collectible object is close enough to G.E.A.R and therefore we might collect it!
Summary and Possible Improvements
We have created a simulation of an autonomous robot in our custom-made environment using several different approaches. Still, in order to turn the prototype into an actual product, which can deliver business value, there are some improvements which should introduced:
Install the actual mechanism for garbage collection - as mentioned before, the mechanical design of the robot should be simulated in detail. This means installing a “shovel” which could seamlessly push the garbage into the “belly” of a robot. As a result, we should also design a clever and efficient way to dispose the set of items once the robot’s container becomes full.
Deploy the algorithm on a machine which can handle real-time semantic segmentation - the inference time of the semantic segmentation model turned out to be too slow for real-time simulation. This comes mainly from the limited computing power of our laptops. We could easily improve it not only by using professional, industry-grade graphic cards, but possibly rewriting the code using C++ or (in more extreme cases) introducing weights quantization.
Transfer the knowledge from simulation to a real robot with RealSense camera - the final part of the endeavour would be deployment of the robot in the physical environment. This would mean fine-tuning algorithms by running the robot in the real world. To my best knowledge, the use of reinforcement learning in robotics is still in experimental stage. One of the recent undertakings, which translates the results of the RL robot simulation into physical agents is the ANYmal project. We could use similar approaches to move from Unity 3D engine to the actual world. It would be really exciting to explore how G.E.A.R would do in the complex, real-life domain!
